Ingest Millions of Messages in the Queue using Serverless
While working on one of the Serverless projects, We came across a problem where I needed to ingest millions of messages from an external API to Azure Storage Queue. We made a series of changes in my approach to reach the solution which worked for us and I believe it can be helpful to anyone who’s struggling with the same problem.
We started with the approach where we were executing the Serverless function through the HTTP endpoint. We call it an Ingestion Function. The ingestion function would then hit an external API to get the messages and try to ingest it in Queue.
Here is how my initial architecture looked like:
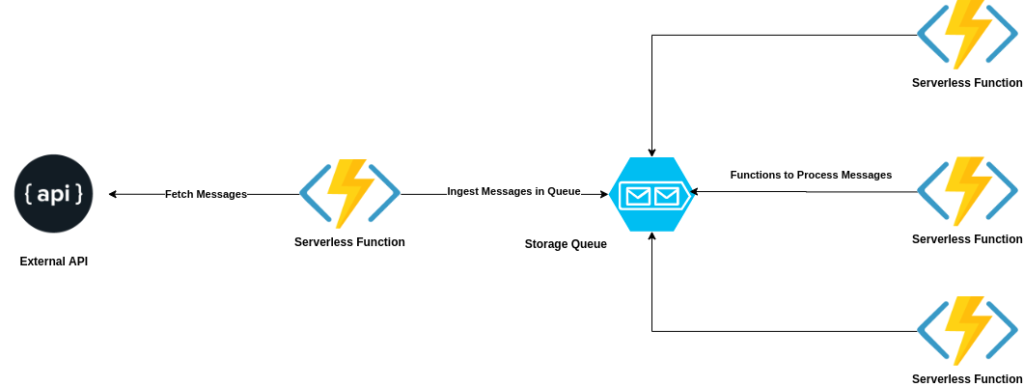
If you see the architecture diagram, the single ingestion function is a bottleneck as it can only scale up-to specific limits. Also, we’re not utilizing the strength of the actual serverless function, which is multiple parallel small invocations. Therefore, we decided to go with the approach where I could scale up the ingestion serverless to multiple invocations so that I can get the scalability as much as needed.
The idea was to divide the total number of messages into multiple chunks (of 5000 in my case) and then pass those messages to the ingestion function so that it can finally ingest those messages to the Queue.
We created another serverless function, we call it Chunking Function, to divide the messages into chunks using this helper function:
def chunking_of_list(data): """return the list in 5000 chunks""" return [data[x:x+5000] for x in range(0, len(data), 5000)]
And then uploaded each chunk in a separate file into Azure Blob Storage using this code:
def upload_chunks(idLists):
st = storage.Storage(container_name=constant.CHUNK_CONTAINER)
for index, singleList in enumerate(idLists):
logging.info('Uploading file{0} to the {1} blob storage' .format(index, constant.CHUNK_CONTAINER))
st.upload_chunk('file' + str(index), singleList)
Finally, we set up the ingestion function to listen to the Azure Blob Storage file upload events. As soon as the file gets uploaded, the ingestion function will download the file, read it, and ingest the messages into Queue. As desired we now have multiple invocations of ingestion functions to work in parallel therefore, we achieved scalability.
Here’s how the final architecture looked like:
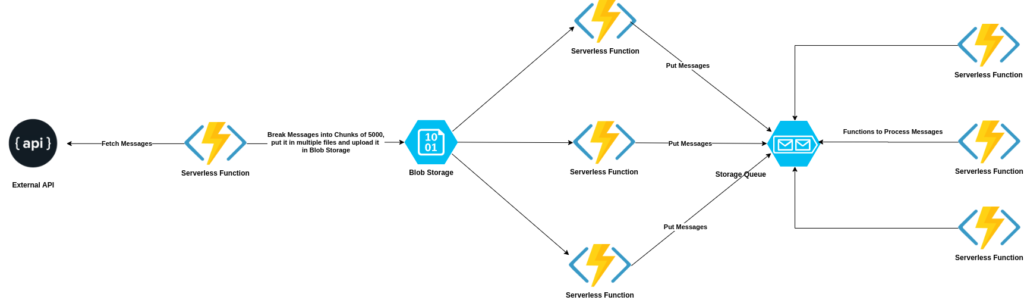
We essentially followed a fan-out architecture, where we fan out our workload to multiple Serverless invocations instead of one.
Peace ✌